Flink
简介
Apeche Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算.Flink能在常见的集群环境中运行,并能以内存数独和任意规模进行计算。
1 | Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale |
为什么用Flink
- MapReduce 核心过程shuffle 会产生大量的IO操作导致性能下降。
- Spark 上位。 基于内存处理数据,但是没有对内存进行很好的管理.
- Flink 实时很优秀(SparkSteaming虽然是也是流但是本质上还是通过批处理的概念去完成的)、兼容流式处理和离线处理(但是没有spark好用)
特性
处理有界和无界数据
有界流:
无界数据: 有定义流开始,但是没有定义流的结束。它们会无休止的产生数据。无界流的数据必须持续处理,即数据提取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常需要以特定的顺序摄取事件, 例如事件发生的顺序,以便能够推断结果的完整性。
像商场的自动扶梯 一直等待顾客。
有界流:
有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行处理计算,有界流所有数据可以被排序,所以不需要有序摄取。有界流处理通常被成为批处理
像电梯 客人按下电梯 进入电梯 关门 运行电梯
运行范围广
YARN、Mesos、Kubernetes
运行任意规模的应用
处理数据量大,节点规模上限大
利用内存提升性能
有状态的Flink程序对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过本地(通常在内存中)状态进行所有的计算,从而产生非常低的数据言辞。Flink通过定期和一步对本地状态持久化来保证故障场景下精确一次的状态一致性。
数据传输策略
在一个dataFlow中会出现多种策略
forward strategy
发送策略
- 一个 task 的输出只发送给一个 task 作为输入
- 如果两个 task 都在一个 JVM 中的话,那么就可以避免网络开销
key based strategy (key by)
按key分组策略(Spark的宽依赖)
- 数据需要按照某个属性(我们称为 key)进行分组(或者说分区)
- 相同 key 的数据需要传输给同一个 task,在一个 task 中进行处理
broadcast strategy
广播策略
- 上游task的输出会发送到下游所有的task作为输入
random strategy
随机策略
- 数据随机的从一个 task 中传输给下一个 operator 所有的 subtask
- 保证数据能均匀的传输给所有的 subtask
Task Slot
Operator Chain
算子链
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
task合并 将多个task合并成一个task
条件
- 数据传输策略是 forward strategy keyBy、sum、print等操作
- 在同一个TaskManager中运行
- 并行度一致
四层运行模型
一个dataFlow提交到Flink上执行需要经过下面4种阶段
- Stream Graph
我们编写代码的流程写代码的任务流程例如:
source -> flatMap -> keyed sum -> sink - Job Graph
对Stream Graph种进行优化,比如说看是否有Opwrator Chain
source -> flatMap -> keyed sum + slink - Execution Graph
相对于Job Graph增加了并行度的处理 - Physical Execution Graph (三层模型没有这玩意)
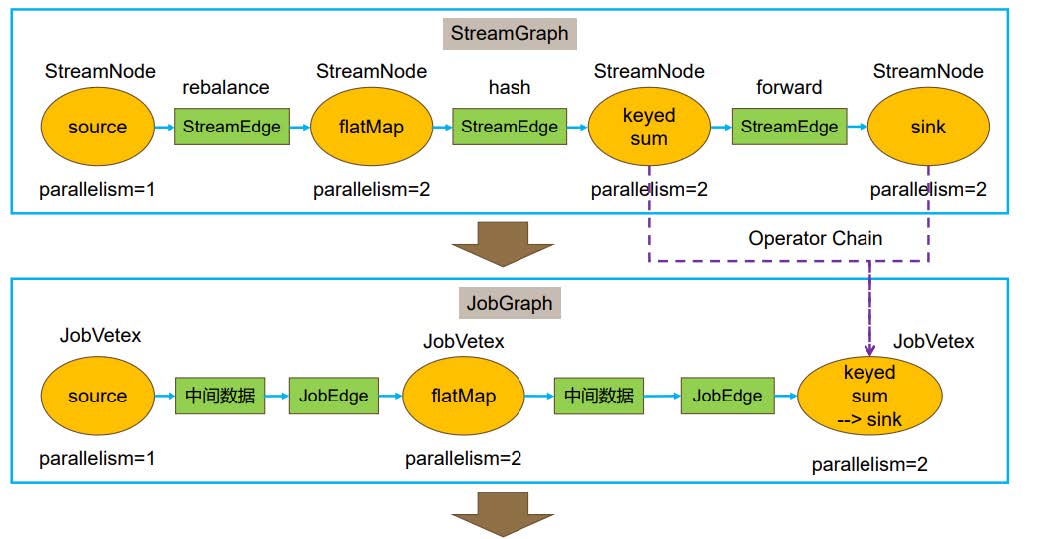
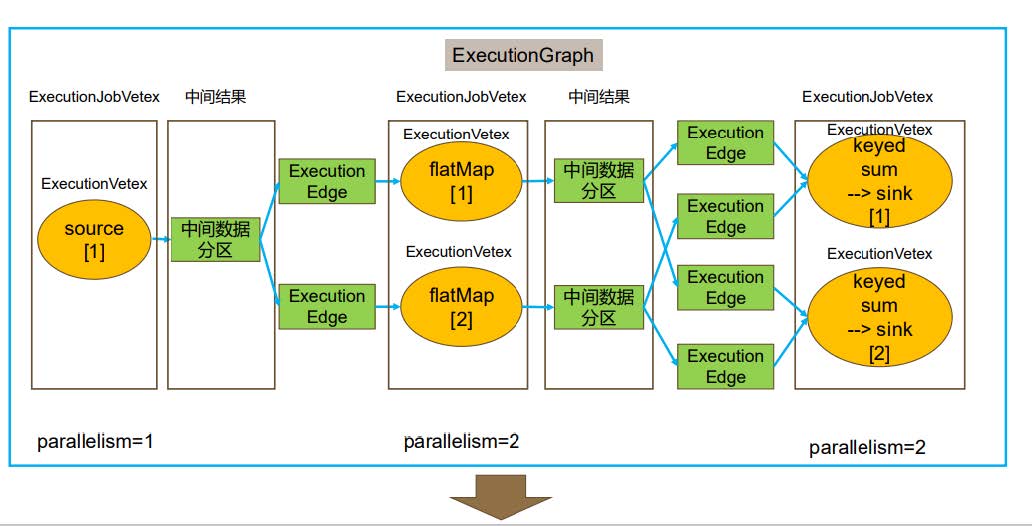
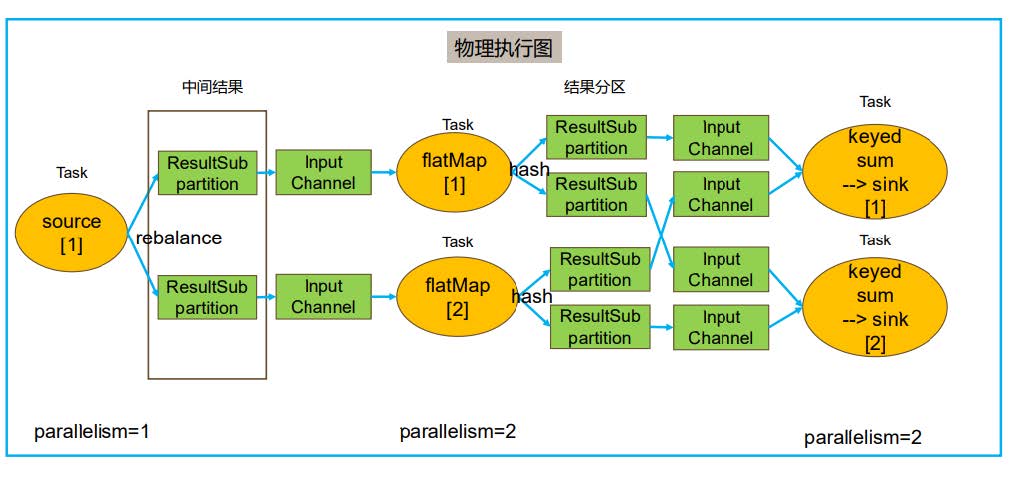
Flink任务分布式运行流程
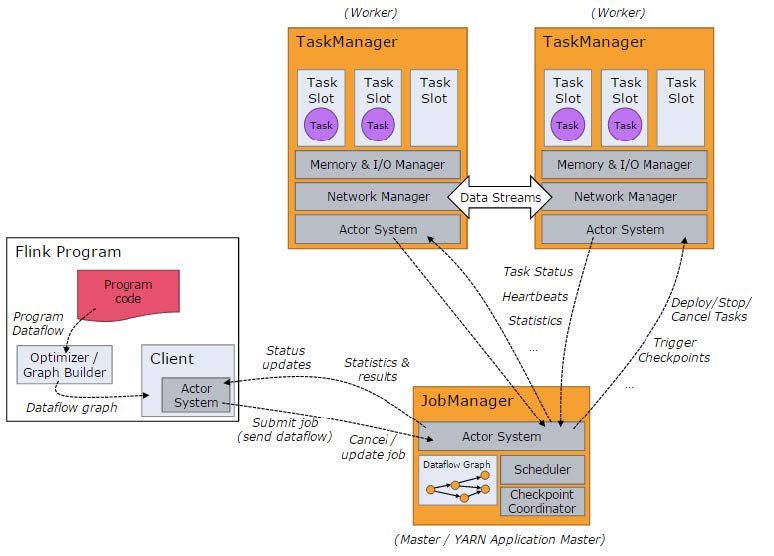
TaskManager
从节点,任务(Task)运行于此
TaskManager之间的数据传输通过Netty
TaskSlot封装内存网络等资源
JobManager
主节点
与TaskManager通过Akka方式通信(正在往netty升级)
运行流程
代码(Program Code)提交到Flink环境执行flink run后构建为 Stream Graph -> 优化为Job Graph(以上两步称为 Optimizer/Gpaph Builder) -> Submit Job到JobManager -> 加入并行度后变成 Execution Graph -> 通过Scheduler将任务分发调度到Task -> 任务运行中TaskManager将Task Status, Heartbeats,Statistics发送给JobManager
基础操作API
source
输入数据
readTextFile() 读取文本文件
socketTextStream() 从socket中读取数据
fromCollection() 从集合中读取数据
addSource() 读取第三方数据源(例如kafka、自定义数据源))
transformation
数据处理
map
对数据值进行处理
场景:将数据补齐 1234-> order:1234
和flatMap的区别。map是数据原数据值进行处理,无法改变流你没办法在流中删除某个数据不让他发送到下游。 flatMap可以改变流内容filter
对数据元进行过滤,true表示放行;false表示过滤
场景:过滤异常数据union
合并多个输入流(合并的流类型必须一致)
场景:需要处理N个不同日志数据connect
链接两个流并且连个流数据类型可不一致splic&select
更具规则将数据切分为多个流,然后通过select获取指定流
场景:订单日志不同类型的订单不同处理
sink
输出数据
- print() / printToErr()
- writeAsText()
- addSink()
state
指具体的task/operator的状态。state可以被记录(数据的中间接过),失败下可以的情况下可以被恢复.
按状态区分为:
托管状态:由Flink框架管理的状态。 常用
原始状态:由用户自行管理状态具体的数据结构, 框架在checkpoint的时候,使用byte[]来读写内容,对其内部数据结构一无所知。通常在DataStream上的状态推荐用托管的状态,当实现一个用户自定义的operator时,会使用到原始状态。不常用
Keyed State
经过keyBy算子计算的 (常用)
经过keyBy计算后每个task中包含多个state,也就是每个key对应一个state
托管状态:
ValueState
ListState
MapState
ReducingState
AddregatingState
operator State
未经过keyBy算子计算的 (不常用)
state是task级别的state,也就是每个task对应一个state
自定义 state
State backend
确定state保存位置
MemoryStateBackend
默认方式
状态信息存储在TaskManager 的堆内存中,checkpoint 的时候将状态保存到jobManager的堆内存中
缺点:
只能保存数据量小的状态
状态数据可能丢失(因为在内存中)
优势:
开发测试方便其实就是代码量小了
性能高
FsStateBackend
用于大部分生产情况(状态大小较小)
Fs 可以理解 File System
状态信息存储在TaskManager 的堆内存中, checkpoint 的时候将状态保存到指定的文件中(HDFS等文件系统)
缺点:
状态大小受限于TaskManager内存限制(默认支持5M) 为啥memory 没有这个缺点?
优点:
状态访问速度快
状态信息不会丢失
RocksDBStateBackend
用于大部分生产情况(状态大小较大)
状态信息存储在RocksDB 数据库,最终保存在本地文件中,checkpoint的时候将状态保存到指定的文件系统中
缺点:
状态访问速度没有之前的高
优点:
可以存储超大量的状态信息
状态信息不会丢失
StateBackend配置方式
全局
修改flink-conf.yml
(不建议)
1 |
局部
CheckPoint
flink可靠性的保证, 可以保证Flink集群在某个算子因为某些原因出现故障时能将整个应用流图的状态回复到故障之前的某个状态,保证应用流图状态的一致性
SparkStream的 checkpoint无法实现仅一次处理
任务运行时执行checkpoint将当前的阶段数据及状态记录下来。下次计算是因为宕机或者其他原因某个计算出现异常,flink自动重启获取checkpoint中的数据 继续计算
默认只保留最近生成的一个checkpiont, 如需要支持多个修改配置指定checkpoint数量
1 | conf/flink-conf.yaml |
Chandy-Lamport 算法
类似开会本来要等大家一起开会汇报进度。现在弄了一个在线表格,任务在前的先汇报记录然后流转给下一个任务人(可以等他忙完)然后继续流转。最终到测试汇总然后汇报结束
- 运行任务
- JobManager 发起CheckPoint
JobManager 向任务流中发送 barrier (栅栏) - source上报CheckPoint
source收到barrier 向JobManager上报完成CheckPoint 将source的数据存储(保存位置由设置的StateBackend确定)。并将barrier 通过广播方式发送到下个task - 数据处理
在barrier到达task之前的数据按业务继续处理。收到barrier后的数据需要缓存
这里有精确一次处理(数据缓存) 和 至少一次处理(不缓存继续发送给下个task)的区别 - barrier对齐
在所有的barrier到达后,对task的状态进行checkpoint并将barrier发送到下个task
这里如何判断所有的barrier都到了? - 缓存数据处理
在所有的barrier到达最后的Sink后,上报JobManager完成checkPoint. 通知存储checkpoint结束
重启策略
Flink支持不同的重启策略,以在故障发生时控制作业如何重启,集群在启动时会伴随一个默认的重启策
略,在没有定义具体重启策略时会使用该默认策略。 如果在工作提交时指定了一个重启策略,该策略会
覆盖集群的默认策略,默认的重启策略可以通过 Flink 的配置文件 flink-conf.yaml 指定。配置参数
restart-strategy 定义了哪个策略被使用
如果没有启用checkpoint默认不启用重启策略
如果启用checkpoint但是没有配置重启策略默认用固定间隔策略。重启次数默认值是:Integer.MAX_VALUE
固定间隔(Fixed Delay)
1 | 第一种:全局配置 flink-conf.yaml |
失败率(Failure rate)
1 | restart-strategy: failure-rate |
无重启(No restart)
1 | 第一种:全局配置 flink-conf.yaml |
SavePoint
SavePoint是一个重量级的Checkpoint, 某个时间点上整个程序的状态的全局镜像
主要用于程序升级、代码升级、参数修改
和checkpoint的区别
- 概念区分
Checkpoint-> 自动容错机制;
Savepoint-> 程序全局状态镜像; - 功能作用区分
Checkpoint-> 是程序自动容错,快速恢复;
Savepoint-> 是程序修改后继续从状态恢复,程序升级; - 触发条件区分
Checkpoint-> Flink系统行为;
Savepoint-> 用户触发; - 状态文件保留区分
Checkpoint-> Checkpoint默认程序删除,可以设置CheckpointConfig中的参数进行保留
Savepoint-> 会一直保存,除非用户删除
Windows
TimeWindows
Time种类
- Event Time
事件产生的时间,它通常由事件中的时间戳描述。
Flink牛逼的地方
Ingestion time
事件进入Flink的时间(一般不用)Processing Time
事件被处理时当前系统的时间
SparkStream 只有这个时间没有其他时间
WaterMark
处理乱序时间(EventTime)
通过增加windows的长度(水位)处理一些迟到的事件
当窗口被触发后,在进来窗口时间段内的事件也不会接收会被抛弃。比如设置窗口截止是00:05 然后进来了 03、04然后进来了06导致窗口触发了这时候在进来04时间的数据也不会被接受; 但是可以通过API来补偿处理这些数据(侧输出流)
有序数据
数据正常顺序的进来
TimeWindowWordCount
输出
1 | (hadoop,2) // 第15s 的时候 检测到 13s发出的两个hadoop |
无序数据
数据乱序的进来
正常情况下第 13 秒的时候连续发送 2 个事件,但是有一个事件确实在第13秒的
发送出去了,另外一个事件因为某种原因在19秒的时候才发送出去,第 16 秒的时候再发送 1 个事件
默认什么都不处理的情况
SumProcessWindowFunction
输出
1 | (hadoop,1) // 第15s 的时候 检测到 13s发出的一个hadoop |
通过EventTime处理无序数据
TimeWindowWordCountEventTime
输出
1 | (hadoop,1) // 第15s 的时候 检测到 13s发出的一个hadoop |
输出时间
1 | 当前窗口时间: 17:56:10 |
第25s的时候收到第13s的数据已经过滤了。 但是13s的时候没有收到。 因为窗口在15s的时候事件还没发出等到发出的时候已经进入到另外的window了
通过增加WaterMark 处理乱序
TimeWindowWordCountWaterMark
输出
1 | (hadoop,2) // 第15s 的时候 检测到 13s发出的一个hadoop + 通过增加水位 在19s发出的原本在13s就应该发出的一个hadoop |
输出时间
1 | 当前窗口时间: 17:56:10 |
窗口的总长没有发生变化 变化的是窗口的处理时间 延迟了5s
QA
在做 ProcessWindowFunction 练习wordCount的时候。由于没有用Tuple2用了自定义的对象。然后keyBy直接用的
keyBy("fieId")案例里面用的是Tuple2然后keyBy用的是lambda获取的。在实现ProcessWindowFunction的时候就按照样例里面KEY的类型是String1
class SumProcessWindowFunction extends ProcessWindowFunction
但是这样在
.process(new SumProcessWindowFunction())的时候出现了error告知我KEY的类型应该要用Tuple。对照了很多遍没发现问题,也没觉得是keyBy的问题。按照提示换成Tuple1
2
3
4public class SumProcessWindowFunction extends ProcessWindowFunction
// 输出
out.collect(new WordCountModel(keyTuple.getField(0), count));这样确实也能玩但是总感觉很怪异。 后面对了一下flink版本发现样例用的是1.12的版本。升级后Key类型设定为String 还是报错。 但是
keyBy("fieId")出现了启用的warning。换成lambda获取后正常无报错1
keyBy(WordCountModel::getWord)
1
2
3
4
5
6
7
8
9
10
11public class KeyedStream
@Deprecated
public KeyedStream
return this.keyBy((Keys)(new ExpressionKeys(fields, this.getType())));
}
publicKeyedStream
Preconditions.checkNotNull(key);
return new KeyedStream(this, (KeySelector)this.clean(key));
}查看源码可以发现KeyedStream的两个泛型第二个是KEY的类型
两个keyBy 通过field作为入参的强制使用的Tuple, 通过KeySelector使用了lambda的EventTime 是事件驱动的时间,但是案例里面其实就是日志里面的一个字段数据。为什么这里说牛逼?
滑动窗口时间分段的问题
如果按照窗口大小10s 滑动时间5s的话Flink划分的窗口就是1
2
3
4
5
6
7[00:00:00, 00:00:05) [00:00:05, 00:00:10)
[00:00:10, 00:00:15) [00:00:15, 00:00:20)
[00:00:20, 00:00:25) [00:00:25, 00:00:30)
[00:00:30, 00:00:35) [00:00:35, 00:00:40)
[00:00:40, 00:00:45) [00:00:45, 00:00:50)
[00:00:50, 00:00:55) [00:00:55, 00:01:00)
[00:01:00, 00:01:05) ...如果你在00:00:02执行的程序。触发的时间还是在00:00:05而不是00:00:08。
1
.window(SlidingProcessingTimeWindows.of(Time.seconds(11), Time.seconds(7)))
如上代码所示,窗口为11s, 滑动时间为7s 都是60无法乘除的,时间分段是怎么分的起始时间怎么来的?
查看源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26package org.apache.flink.streaming.api.windowing.assigners;
public class SlidingProcessingTimeWindows extends WindowAssigner
......
@Override
public CollectionassignWindows(Object element, long timestamp, WindowAssignerContext context) {
timestamp = context.getCurrentProcessingTime();
Listwindows = new ArrayList<>((int) (size / slide));
long lastStart = TimeWindow.getWindowStartWithOffset(timestamp, offset, slide);
for (long start = lastStart;
start > timestamp - size;
start -= slide) {
windows.add(new TimeWindow(start, start + size));
}
return windows;
}
......
}
package org.apache.flink.streaming.api.windowing.windows;
public class TimeWindow extends Window {
// Method to get the window start for a timestamp.
public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) {
return timestamp - (timestamp - offset + windowSize) % windowSize;
}
}SlidingProcessingTimeWindows中实现了WindowAssigner接口的assignWindows方法。里面计算得到了lastStart, 这里 timestamp获取了当前程序的运行时间 timestamp - (timestamp - offset + windowSize) % windowSize 取了比timestamp小的最近的一个能被windowSize整除的时间戳
new TimeWindow(start, start + size)窗口和窗口的时间间距就是slide 窗口的长度也就是sizeList的长度也就是size/slidewindows
比如说程序时间是 1589681103000(2020-05-17 10:05:03) 那windows中的数据就是1
2
3
4
5TimeWindow{start=1589681100000, end=1589681700000};
TimeWindow{start=1589681095000, end=1589681695000};
TimeWindow{start=1589681090000, end=1589681690000}
......
TimeWindow{start=1589680505000, end=1589681105000}test
flink结果导出到es通过kibana展示案例
每隔5分钟统计最近1小时的热门商品(这里定top5)
需求拆解:
滑动窗口 长度 3600s;滑动时间 5min
计算窗口内的Top5
